News center
[입학팀X알리미] 이공계 진로 설계 안내서
[과학이야기] 기획특집 ③ Physical AI
- 등록일2026.05.18
- 조회수444
기획특집 ③
인지부터 행동까지 한 번에, VLA
글. 전자전기공학과 24학번 30기 알리미 정찬우은재학부 25학번 31기 알리미 백지훈
지금까지는 인공지능의 사고 체계와 감각 기관의 발전을 다뤘다면, 이제는 ‘움직임’에 주목할 때입니다. 이번 꼭지에서는 스스로 상황을 판단하고 움직이게 만드는 핵심 기술인 VLA(Vision-Language-Action) 모델에 대해 알아보겠습니다.
통합 아키텍처, VLA의 등장
과거의 로봇 제어 시스템은 시각 인식, 언어 이해, 행동 제어의 세 가지 기능이 독립된 모듈로 설계되었습니다. 따라서 속도가 느리고, 일반화 능력이 낮았습니다. 이러한 문제를 해결하기 위한 기술이 바로 VLA입니다. VLA 모델은 시각, 언어, 상태, 행동이라는 서로 다른 형태의 정보를 공통 표현 공간에서 통합하고, 이를 바탕으로 로봇의 행동을 예측하는 구조를 채택합니다. 특히 일부 VLA 모델은 로봇의 연속적인 행동을 이산적 토큰(Discrete Tokens)으로 변환해 언어 모델처럼 다음 행동을 생성합니다.
이때, 토큰이란 무엇일까요? 우리가 긴 문장을 단어별로 나누어 읽으며 문맥을 파악하듯이, 토큰이란 인공지능이 정보를 이해하고 처리하기 위해 데이터를 쪼갠 ‘최소 단위’를 의미합니다. 액션이나 이미지와 같이 서로 다른 형태의 데이터를 토큰 또는 임베딩 형태로 변환한 뒤, Transformer와 같은 신경망 구조 안에서 하나의 연속적인 정보 흐름으로 통합하는 것이 VLA 모델의 핵심입니다.
실제 상황에서 VLA 모델이 어떻게 작동하는지 구체적인 예시를 통해 이해해 볼까요? 로봇에게 ‘빨간 쟁반 위에 초록색 블록을 쌓아라’라는 지시가 내려진 상황을 가정해 보겠습니다. 이 명령을 수행하기 위해 모델은 크게 세 단계의 연산을 수행합니다.
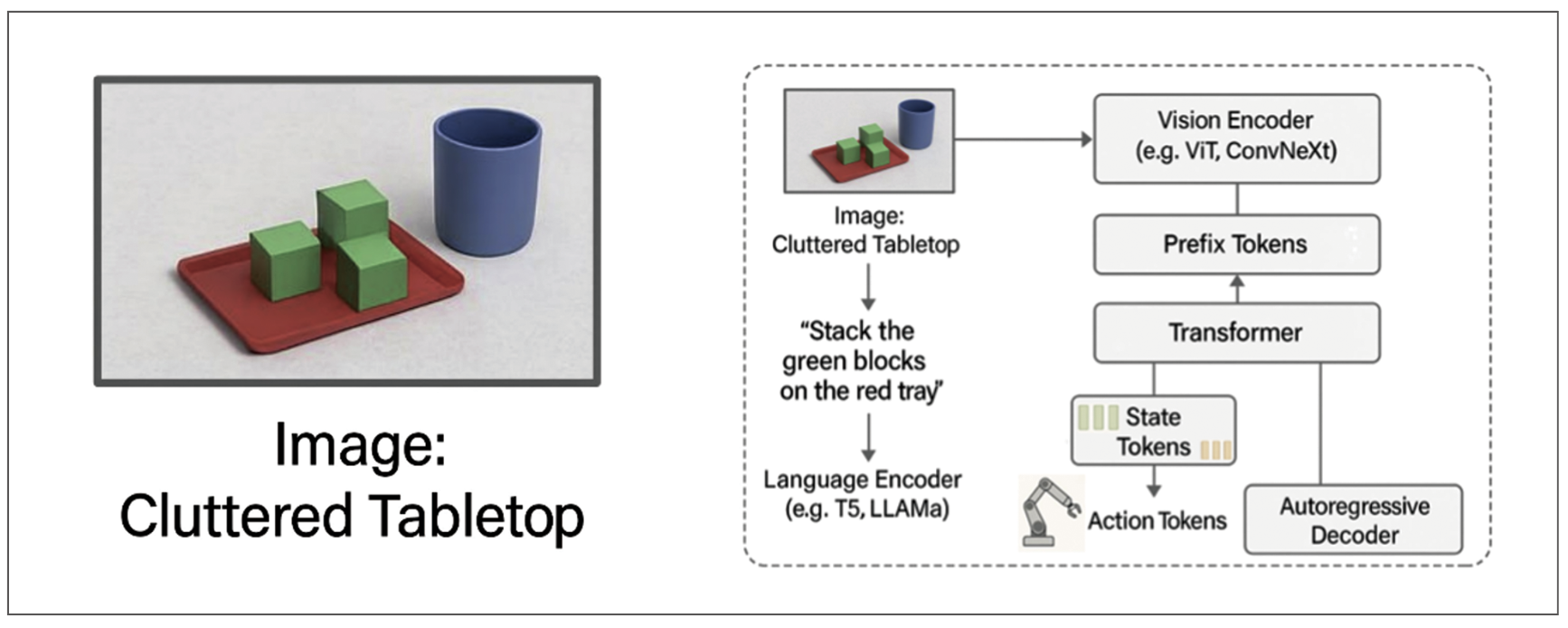
그림 1. 주어진 문제 상황과 ViT 로직의 모식도
가장 먼저, 모델은 카메라를 통해 실시간으로 들어오는 시각 정보를 분석합니다. 모델은 테이블 위에서 ‘빨간 쟁반’, ‘초록색 블록’ 등을 비전 인코더를 통해 인코딩1하고, 이를 토큰화하여 임베딩 공간에 투영합니다. 이때 사용되는 핵심 기술이 바로 ViT2입니다. ViT는 아래 과정을 통해 이미지의 의미를 추출합니다.
우선 이미지를 작은 패치로 쪼개는 이미지 패치 분할을 진행합니다. 이후 각 패치를 벡터로 펼친 뒤, 전체 맥락을 담는 분류 토큰과 각 조각의 공간 정보를 보존하는 위치 임베딩을 추가합니다. 생성된 각 벡터는 Transformer를 통해 처리되어, 단순한 객체 인식을 넘어 ‘빨간 쟁반 위 초록색 블록’과 같은 사물 간의 공간적 상관관계를 이해하게 됩니다.
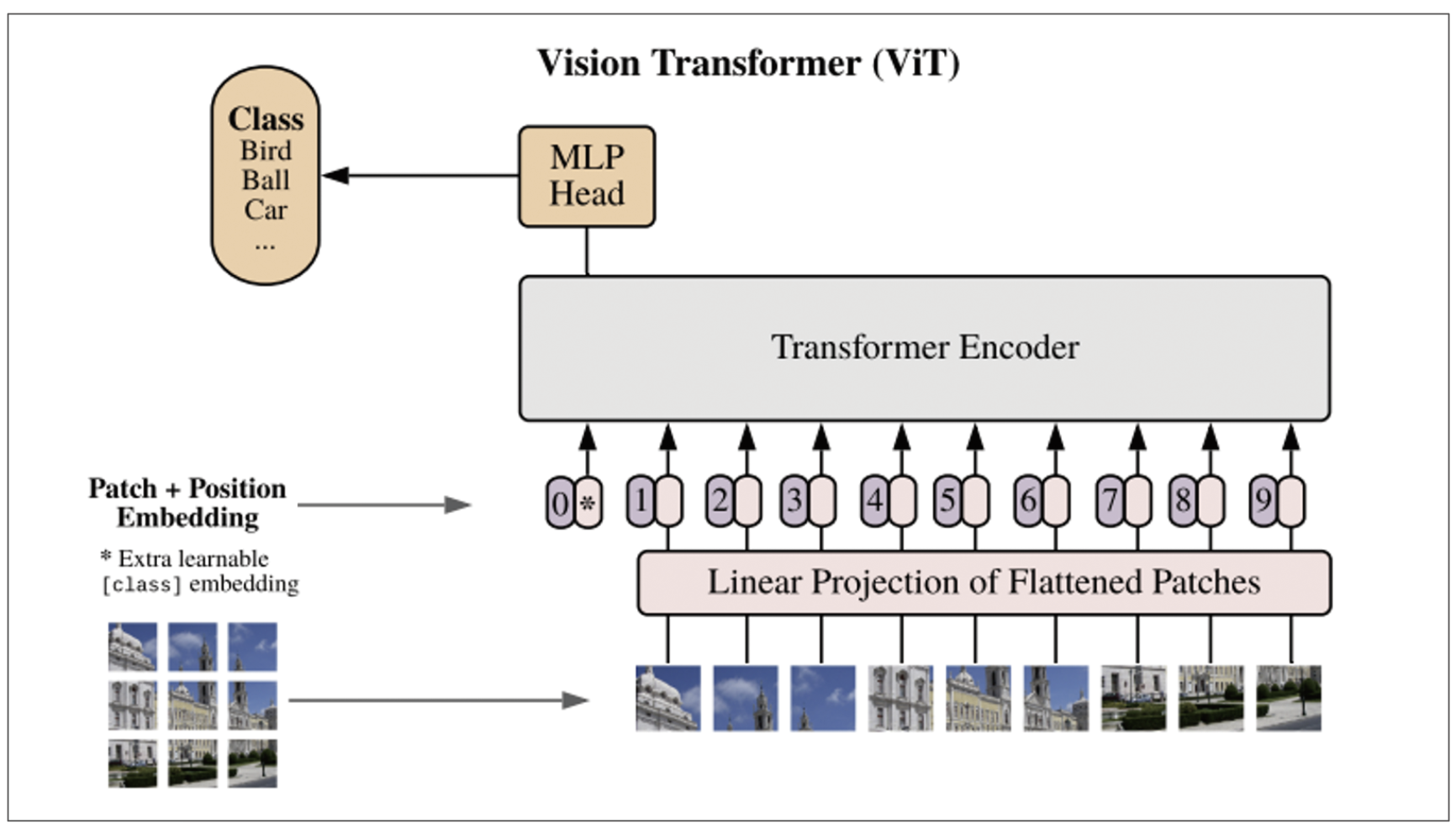
그림 2. ViT 모델의 이미지 패치 분할과 평탄화 과정, 위치 임베딩 추가 모식도
이어서, 시각 분석과 동시에 BERT3 모델과 같은 언어 모델을 통해 인간의 명령을 해석합니다. BERT는 텍스트 지시문을 언어 토큰으로 변환한 뒤, 문장 전체를 앞뒤로 분석하는 양방향 문맥 파악 기술을 이용해 단어의 수식 관계를 익힙니다.
마지막으로, 시각 및 언어 토큰과 로봇의 물리적 상태를 나타내는 상태 토큰을 교차주의(Cross-attention) 메커니즘을 통해 하나로 융합합니다. 이 과정에서 여러 정보들이 유기적으로 결합되어 실제 로봇의 정교한 움직임이 만들어집니다.
교차주의는 질문(Query), 키(Key), 값(Value)이라는 세 가지 벡터의 상호작용으로 정의됩니다.
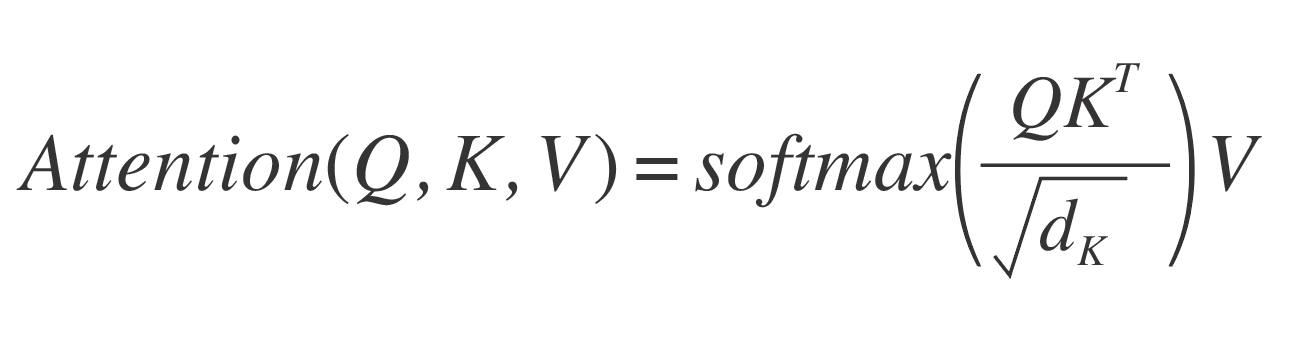
Q는 현재 처리 중인 정보를, K는 입력된 시각 및 상태 데이터 벡터, V는 각 데이터의 실제 표현 값을 의미합니다. 모델은 Q와 K의 내적을 계산해 두 정보가 얼마나 관련되어 있는지 판단합니다. 이후, 계산의 결과를 Softmax 함수4로 정규화한 뒤 V에 가중치를 부여합니다. 이를 통해 모델은 분석한 데이터를 바탕으로 핵심 정보를 파악한 후, 향후 움직임을 계산합니다.
사고하는 로봇, DVLA
VLA는 입력된 정보를 기반으로 목표를 위한 동작을 생성하지만, 복잡한 상황에서의 단계적인 판단에 있어 한계를 가졌습니다. 위 문제를 해결하기 위해 ‘사고’를 담당하는 리즈닝(Reasoning) 과정을 정책망의 내부 연산 과정에 직접 주입(Injection)하는 DVLA 모델이 등장했습니다.
그렇다면 DVLA는 어떠한 방식으로 ‘사고하는 능력’을 갖게 된 것일까요? 그림 3 모식도를 통해 알아봅시다!
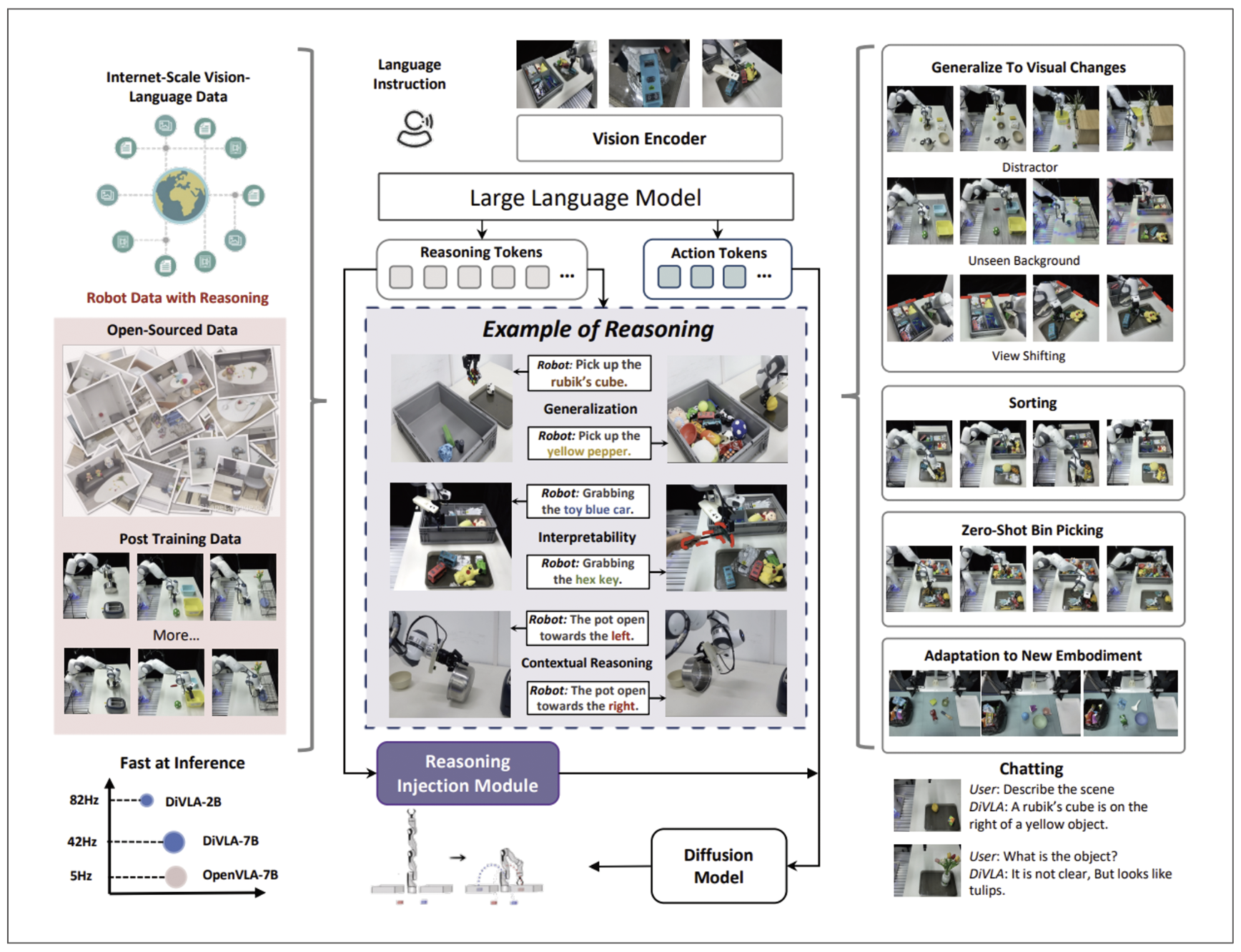
그림 3. DVLA 모델의 모식도
핵심은 모델이 생성하는 ‘추론 토큰’에 있습니다. 모식도 중앙의 정보 처리를 담당하는 핵심 파이프라인에서, 사용자의 명령은 비전 인코더와 언어 인코더를 각각 거쳐 LLM(Large Language Model)으로 전달됩니다. 이후 LLM은 VLA와 같이 바로 행동을 제어하지 않고, ‘추론’이라는 중간 단계를 먼저 생성해 냅니다.
로봇의 사고 과정인 추론의 종류로는, 낯선 환경에 유연하게 대처하는 일반화 추론, 행동의 의도를 인간에게 논리적으로 설명하는 해석 가능 추론, 그리고 정교한 제어를 돕는 맥락 기반 추론으로 나뉩니다. 위 추론 정보들을 리즈닝 인젝션 모듈(Reasoning Injection Module)을 통해 네트워크의 연산 과정에 주입합니다. 덕분에 동일한 객체라도 “컵을 집어라”와 “컵을 밀어라”처럼 명령에 따라 특징에 대한 해석을 달리하는 조건부 변조 등이 가능해지며, 전체적인 성능과 논리성이 강화됩니다.
그 결과 정책 헤드5는 본연의 임무인 액션 토큰 생성에 온전히 집중하고, 추론 모듈은 보조 신호로서추론과 행동 사이의 간극을 성공적으로 메우게 됩니다. 즉, DVLA는 ‘행동을 생성하는 모델’에서 나아가, ‘사고한 뒤 행동을 수행하는 모델’로서, 성공적으로 다양한 환경에 대해 원하는 목적을 달성할 수 있습니다.
지금까지 인공지능이 Zero-Shot Learning에서 임베딩 공간을 통해 세상을 정의하는 과정부터, 도메인 적응(DA)과 랜덤화(DR)를 통해 현실의 높은 벽을 허무는 과정을 거쳐, VLA 모델을 활용해 물리적 실체로 구현하는 거대한 여정을 함께 살펴보았습니다.
이러한 기술적 도약은 시각적 정보만으로 복잡한 사고 체계를 구축하는 CoT-VLA와 실패 경험을 학습에 반영하는 자가 강화 학습 기술로 이어지는 등, 피지컬 AI의 한계를 매 순간 경신하고 있습니다. 현실 세계와 상호작용하는 AI의 시대, 그 중심에 서 있는 VLA 기술의 미래를 앞으로도 지켜봐 주시기 바랍니다!
[각주]
1. 정보의 형태를 표준화, 보안, 처리 속도 향상, 저장 공간 절약 등을 위해 다른 형태나 형식으로 변환하는 과정
2. Vision Transformer의 약자
3. Bidirectional Encoder Representations from Transformers의 약자
4. 입력값을 0과 1 사이의 확률값으로 변환하는 함수로, 다중 분류 과정에서 주로 사용
5. 사전 학습된 비전-언어 모델(VLM)의 이해 능력을 바탕으로, 로봇의 실제 행동을 출력하는 최종 계층
[ 그림 출처 ]
그림 1. Ranjan Sapkota et al., “Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges,” arXiv, arXiv:2505.04769, 7 May 2025, p. 7.
그림 2. Alexey Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” arXiv, arXiv:2010.11929, 22 Oct 2020, p. 3.
그림 3. Junjie Wen et al., “Diffusion-VLA: Generalizable and Interpretable Robot Foundation Model via Self-Generated Reasoning”, arXiv, arXiv:2412.03293, 4 Dec 2024, p. 1.
[ 참고 자료 ]
1. Ranjan Sapkota et al., “Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges,” arXiv, arXiv:2505.04769, 7 May 2025, pp. 5-10.
2. Junjie Wen et al., “Diffusion-VLA: Generalizable and Interpretable Robot Foundation Model via Self-Generated Reasoning”, arXiv, arXiv:2412.03293, 4 Dec 2024, pp. 1-8.
3. Ashish Vaswani et al., “Attention Is All You Need”, arXiv, arXiv:1706.03762v7, 2 Aug 2023, pp. 3-8.